El problema que nadie te cuenta sobre traducir PDFs con IA
Intentas traducir un PDF de 300 páginas con ChatGPT o DeepL. Pegas el primer bloque de texto. La traducción es buena. Pegas el segundo bloque. También. Pegas el tercero... y el nombre del protagonista ya no se traduce igual. El término técnico clave del capítulo 1 aparece ahora con otra palabra. El tono formal del documento se ha vuelto informal.
Esto no es un bug. Es el comportamiento esperado de herramientas que no están diseñadas para documentos largos. Cada petición empieza desde cero, sin memoria de lo que vino antes.
Esta guía explica por qué ocurre y cómo traducir PDFs largos manteniendo coherencia de principio a fin.
Por qué las herramientas genéricas fallan con PDFs largos
El problema del contexto
Todos los modelos de lenguaje tienen una ventana de contexto: la cantidad de texto que pueden "ver" al mismo tiempo. ChatGPT 4o tiene ~128k tokens (~96.000 palabras). DeepL no tiene memoria entre traducciones.
Un libro de 300 páginas tiene aproximadamente 90.000-120.000 palabras. Incluso con modelos de contexto largo, hay dos problemas:
- Degradación de calidad: los modelos son menos precisos con los textos que están muy al final de su ventana de contexto
- Sin glosario persistente: no hay mecanismo para garantizar que "contract" siempre se traduzca como "contrato" y no a veces como "acuerdo" o "convenio"
El problema de la coherencia estilística
Un texto largo tiene un estilo. Un autor usa ciertas estructuras sintácticas, cierto nivel de formalidad, ciertas metáforas recurrentes. Una traducción fragmentada en bloques de 5.000 palabras produce un texto donde el estilo fluctúa capítulo a capítulo.
Para novelas esto es especialmente grave: la voz narrativa del autor desaparece en el ruido de las diferentes "versiones" que produce el modelo en cada fragmento.
Tipos de PDF que más sufren este problema
Novelas y libros de no ficción
La coherencia narrativa es todo. Nombres propios, lugares, términos específicos del universo del libro necesitan tratamiento consistente de la página 1 a la página 400.
Manuales técnicos
La terminología técnica es crítica. Un "input/output buffer" no puede traducirse de tres formas diferentes en el mismo manual. Los errores de terminología generan confusión en los usuarios finales y pueden ser un problema de seguridad en manuales de producto.
Documentación legal y contratos
Los términos jurídicos tienen significados precisos. "Breach of contract" no es lo mismo que "incumplimiento contractual" en todos los contextos. Una traducción inconsistente de un contrato de 80 páginas puede crear ambigüedades legales.
Informes corporativos y memorias
La identidad corporativa depende del lenguaje. Una empresa que tiene un tono de comunicación específico no puede permitirse que su memoria anual de 150 páginas tenga tres registros distintos según qué tramo traduje primero.
Cómo traducir un PDF largo correctamente
Paso 1: Extracción del texto
Lo primero es extraer el texto del PDF en un formato editable. Hay dos situaciones:
PDF nativo (generado digitalmente): puedes copiar el texto directamente o usar herramientas de extracción. La calidad es alta.
PDF escaneado (imagen): necesitas OCR (reconocimiento óptico de caracteres) antes de traducir. Herramientas como Adobe Acrobat, ABBYY FineReader o incluso Google Drive pueden hacer OCR con buena calidad.
Paso 2: Elegir la herramienta adecuada
Para PDFs de más de 20-30 páginas, necesitas una herramienta que:
- Procese el documento completo antes de traducir, no fragmento a fragmento
- Construya un glosario interno de términos clave y nombres propios
- Mantenga el estilo del texto original a lo largo de toda la traducción
Las herramientas especializadas para traducción de documentos largos (como Nomos) funcionan con una arquitectura multi-agente: primero analizan el documento entero, extraen la terminología clave y el estilo, y luego traducen cada sección con ese contexto global disponible.
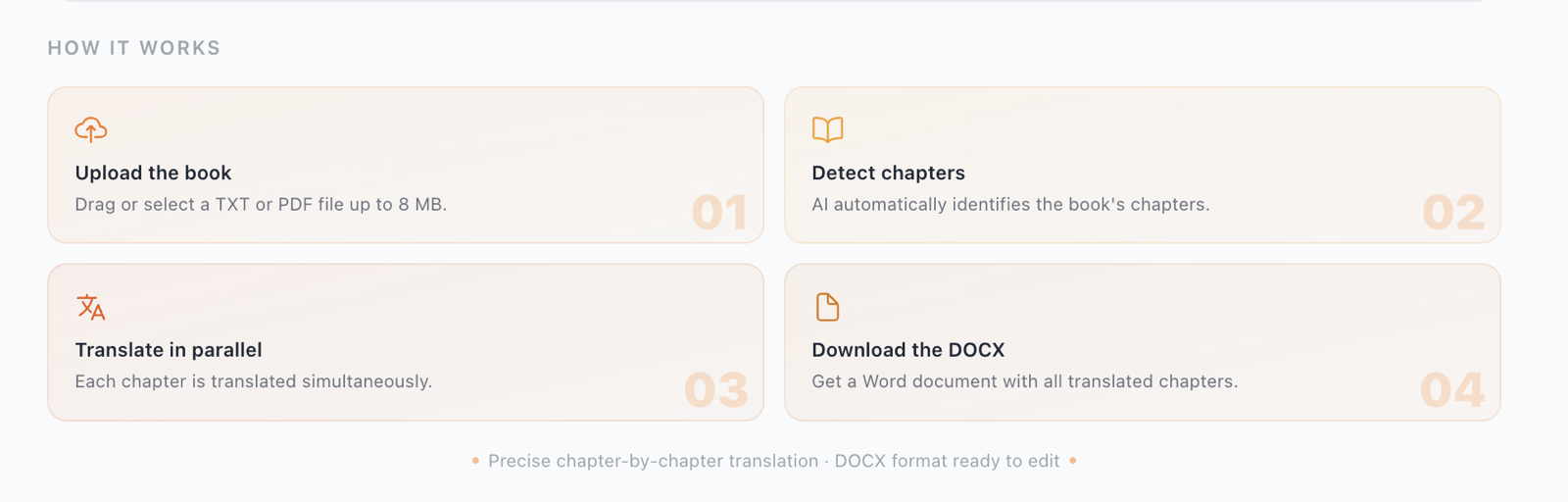
Paso 3: Definir el glosario antes de traducir
Si tienes términos que NO deben traducirse (nombres de productos, marcas, términos técnicos propietarios) o que deben traducirse siempre de una forma específica, defínelos explícitamente antes de lanzar la traducción.
Ejemplo para un manual de software:
- "Dashboard" → no traducir, mantener en inglés
- "User interface" → "interfaz de usuario" (siempre, nunca "interfaz gráfica")
- "Repository" → "repositorio" (nunca "almacén" o "depósito")
Paso 4: Traducir por capítulos con contexto global
La diferencia entre una mala y una buena traducción de PDF largo está en si la herramienta traduce capítulo a capítulo de forma aislada o si mantiene contexto entre capítulos.
El proceso correcto:
- El sistema lee el PDF completo
- Identifica personajes, términos clave, estilo predominante
- Genera un "perfil de traducción" del documento
- Traduce capítulo a capítulo pero usando ese perfil como referencia constante
Paso 5: Revisión del resultado
Incluso con la mejor herramienta, la revisión humana es necesaria para:
- Verificar que los nombres propios se han tratado correctamente
- Confirmar que el tono es consistente con el documento original
- Detectar posibles omisiones en párrafos complejos
- Ajustar el registro en secciones donde el autor cambia deliberadamente de tono
Comparativa: herramientas para traducir PDFs largos
| Herramienta | Documentos largos | Glosario persistente | Exporta a Word | Precio aprox. |
|---|---|---|---|---|
| DeepL Pro | Hasta 50 páginas bien | No | Sí | Suscripción mensual |
| ChatGPT | Fragmentos aislados | No | No | Por uso |
| Google Translate | Fragmentos aislados | No | No | Gratis |
| Nomos | Hasta 200 páginas | Sí (automático) | Sí | Por créditos |
Idiomas y calidad
La calidad de la traducción varía según el par de idiomas. Para el mercado hispanohablante, los mejores resultados se obtienen en:
Pares de alta calidad (español como origen o destino):
- Español ↔ Inglés
- Español ↔ Francés
- Español ↔ Alemán
- Español ↔ Italiano
- Español ↔ Portugués
Pares de calidad media (más complejidad lingüística):
- Español ↔ Japonés
- Español ↔ Chino
- Español ↔ Árabe
Para estos últimos, la revisión humana es especialmente importante en textos literarios o jurídicos.
Conclusión
Traducir un PDF largo con IA es completamente viable en 2025, pero requiere una herramienta diseñada para documentos completos, no para fragmentos aislados. La clave está en el procesamiento del documento entero antes de traducir, el glosario interno y el mantenimiento del estilo a lo largo de toda la traducción.
Si el PDF tiene más de 30 páginas, invertir en una herramienta especializada te ahorrará horas de edición manual para homogeneizar terminología y tono.